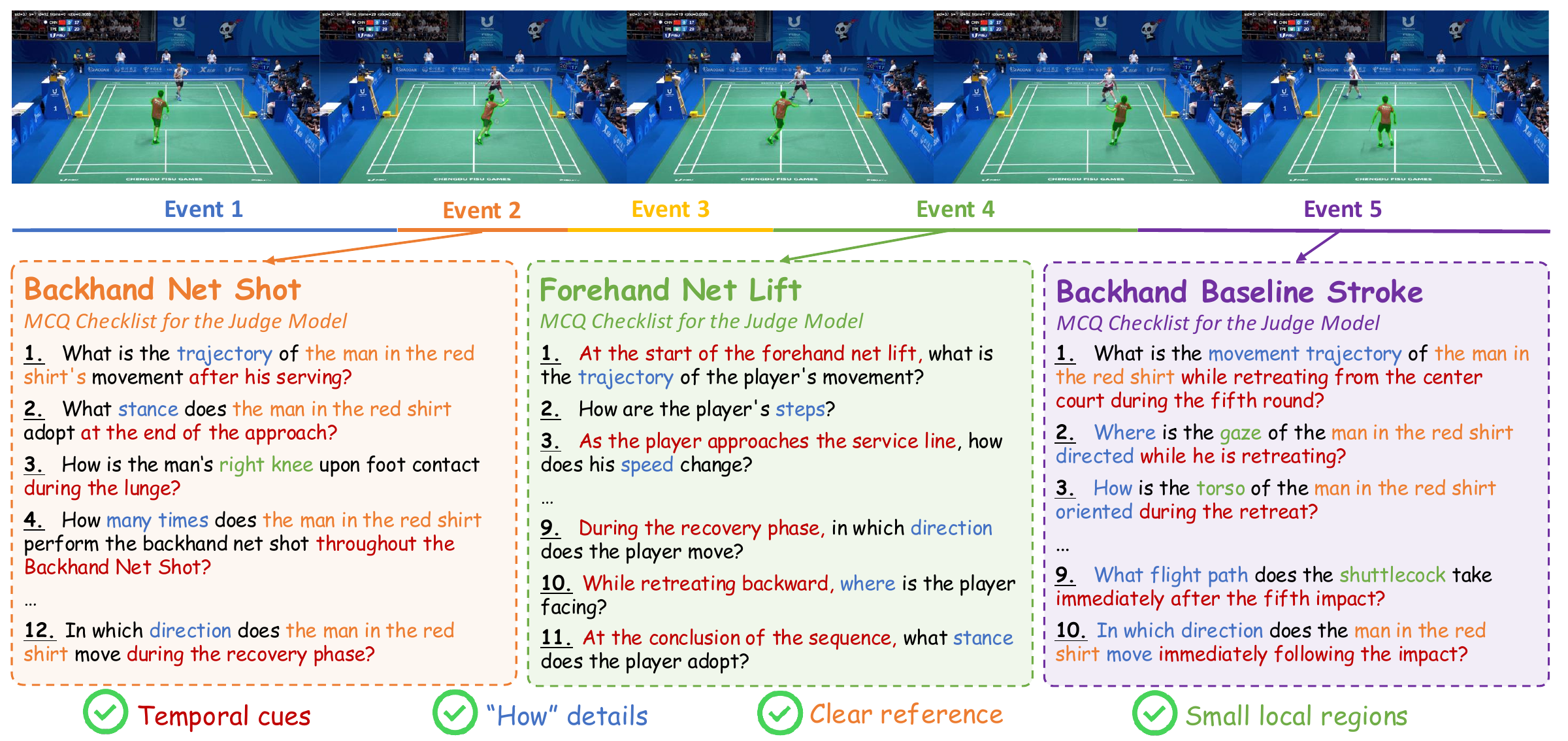
Fine-Grained MCQs
MotionAtlas-Bench uses dense checklist-style questions to judge detailed motion captions over referred objects.
Project Page
1CASIA 2SJTU 3NTU 4PKU 5WHU 6BJTU
TL;DR: MotionAtlas shifts motion captioning from global video descriptions to region-aware motion captions, enabling precise evaluation through MotionAtlas-Bench and scalable training through MotionAtlas-Data.
MotionAtlas-Bench uses dense checklist-style questions to judge detailed motion captions over referred objects.
MotionAtlas-Data provides scalable region-level motion captions refined to suppress fine-grained hallucinations.
MotionAtlas-Data emphasizes dense action verbs and detailed temporal motion descriptions.
Training on MotionAtlas-Data improves both region-level motion captioning and broader motion-related video understanding.
| Model | SF Overall | SF Parts | SF Kin. | FS Overall | FS Parts | FS Kin. |
|---|---|---|---|---|---|---|
| Gemini 3 Pro | 36.4 | 34.7 | 32.0 | 36.5 | 33.5 | 38.1 |
| GPT-5.2 | 36.9 | 34.0 | 34.2 | 37.6 | 38.8 | 36.6 |
| Qwen3-VL-235B | 30.5 | 27.8 | 28.9 | 33.7 | 33.2 | 31.1 |
| Qwen3-VL-4B | 19.3 | 20.0 | 14.1 | 21.7 | 22.4 | 16.5 |
| + MotionAtlas-Data | 27.7 ↑ 8.4 | 27.9 | 26.9 | 30.1 ↑ 8.4 | 30.3 | 29.3 |
| Qwen3-VL-8B | 24.3 | 23.9 | 20.3 | 26.7 | 24.6 | 26.7 |
| + MotionAtlas-Data | 31.6 ↑ 7.3 | 31.2 | 30.6 | 34.1 ↑ 7.4 | 33.6 | 33.0 |
SF = Single-Frame Grounding, FS = Full-Sequence Grounding. Values are accuracy.
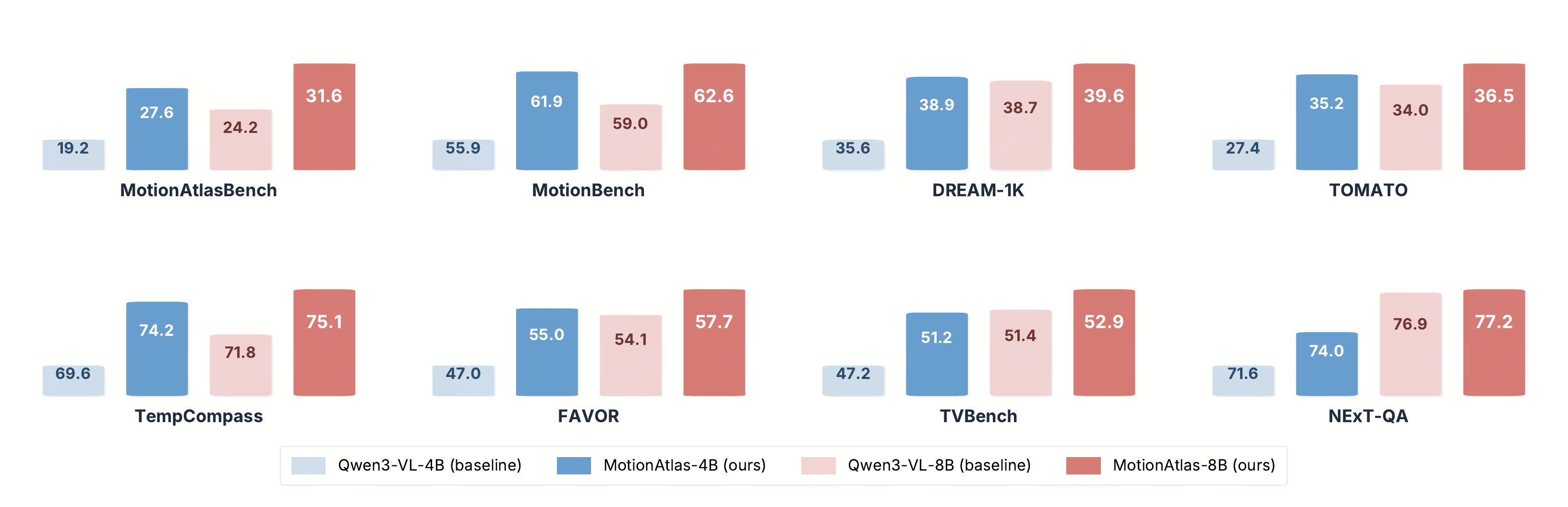
| Model | MotionBench | DREAM-1K | TOMATO | NExT-QA | TempCompass | FAVOR | TVBench |
|---|---|---|---|---|---|---|---|
| GPT-5.2 | 65.4 | 42.2 | 53.0 | 79.9 | 73.0 | 56.8 | 53.8 |
| Gemini 2.5 Pro | 62.0 | 42.7 | 48.6 | 79.8 | 73.7 | 58.8 | 59.9 |
| Qwen3-VL-4B | 55.9 | 35.6 | 27.4 | 71.6 | 69.6 | 47.0 | 47.2 |
| + MotionAtlas-Data | 61.9 ↑ 6.0 | 38.9 ↑ 3.3 | 35.2 ↑ 7.8 | 74.0 ↑ 2.4 | 74.2 ↑ 4.6 | 55.0 ↑ 8.1 | 51.2 ↑ 4.0 |
| Qwen3-VL-8B | 59.0 | 38.7 | 34.0 | 76.9 | 71.8 | 54.1 | 51.4 |
| + MotionAtlas-Data | 62.6 ↑ 3.6 | 39.6 ↑ 0.9 | 36.5 ↑ 2.5 | 77.2 ↑ 0.2 | 75.1 ↑ 3.3 | 57.7 ↑ 3.6 | 52.9 ↑ 1.5 |
| Method | MotionAtlas | MotionBench | DREAM-1K | TOMATO | NExT-QA | TempCompass | FAVOR | TVBench |
|---|---|---|---|---|---|---|---|---|
| Qwen3-VL-4B | 19.2 | 55.9 | 35.9 | 27.4 | 71.6 | 69.6 | 47.0 | 47.2 |
| w/ MotionAtlas-Data | ||||||||
| 20% (32K) | 22.9 | 58.9 | 36.9 | 28.4 | 72.2 | 71.2 | 48.1 | 47.0 |
| 60% (95K) | 24.6 | 59.5 | 37.0 | 30.1 | 73.0 | 72.3 | 50.9 | 49.0 |
| 100% (159K) | 28.3 | 61.9 | 38.9 | 35.2 | 74.0 | 74.2 | 55.0 | 51.2 |
| w/o MotionAtlas-Data | ||||||||
| 20% (32K) | 12.9 | 57.4 | 37.3 | 29.0 | 70.9 | 70.8 | 47.4 | 46.7 |
| 60% (95K) | 12.9 | 58.8 | 36.9 | 30.7 | 71.3 | 72.3 | 50.6 | 47.4 |
| 100% (159K) | 12.2 | 60.5 | 38.3 | 28.4 | 71.9 | 73.3 | 52.2 | 48.5 |
Adding MotionAtlas-Data brings more significant improvements as training data scales.
| Method | Acc | Recall | Precision |
|---|---|---|---|
| MA Pipeline (full) | 39.9 | 68.2 | 58.5 |
| w/o Self-Bootstrap | 36.4 | 64.1 | 56.8 |
| w/o Full-Video Caption | 33.2 | 58.9 | 56.4 |
| w/o Spatial Crop | 32.7 | 60.9 | 53.6 |
Each component contributes to more accurate and recall-rich motion captions.

Each example will pair an input video or frame strip with the referred region and its detailed motion caption.
Placeholder for a detailed region motion caption. Drop an MP4/WebM into assets/videos/ and replace this panel with the final case text.
Placeholder for a caption that describes body-part motion, speed, direction, and temporal order within the referred object.
MotionAtlas uses event segmentation, localized captioning, self-bootstrap verification, and multi-source narrative synthesis to build high-quality motion captions.

@article{liu2026motionatlas,
title={MotionAtlas: Detailed Region Captioning for Motion-Centric Videos},
author={Liu, Weisong and Wang, Haochen and Gao, Kuan and Wang, Yuhao and Zhou, YiKang and Ren, Zhongwei and Mai, Jacky and Wang, Anna and Li, Yanwei and Li, Jason and Zhang, Zhaoxiang},
journal={arXiv preprint},
year={2026}
}